Jupyter Notebook 과 spark은 데이터 처리 분석을 위한 훌륭한 툴이며 이전부터 다양한 회사에서 서비스로 제공해왔습니다. Jupyter Notebook과 Apache Spark을 kubernetes를 이용해서 구성을 하게되면 자체적으로 독립된 resource를 가지고 개발할수 있을수 있어 해당 feature에 대해서 설치를 해보았습니다.
Jupyter Notebook & Spark on Kubernetes in AWS using glue metastore
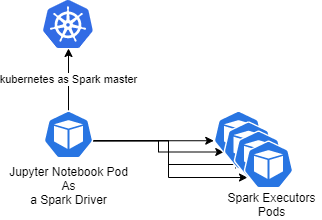
Jupyter Notebook이 driver역할을 하면서 executor를 pod형태로 실행하는 개념입니다.
Jupyter Notebook을 k8s에 설치는 https://github.com/jupyterhub/helm-chart 를 참조해서 설치를 하고, spark on kubernetes에 대해서는 spark page를 참조하시면 되며, AWS에서 spark on kubernetes를 사용하기 위해서는 https://cce199.tistory.com/64 를 참조해서 Image를 생성하면 되겠습니다.
Jupyter Notebook에서 Spark on kubernetes를 사용하는 건 https://towardsdatascience.com/jupyter-notebook-spark-on-kubernetes-880af7e06351 를 주로 참조했으며 AWS환경에서 glue metastore를 사용하는 구성에 필요한 부분을 추가적으로 설명하도록 하겠습니다.
JupyterNotebook Docker Image
# Copyright (c) Jupyter Development Team.
# Distributed under the terms of the Modified BSD License.
ARG OWNER=jupyter
ARG BASE_CONTAINER=$OWNER/scipy-notebook
FROM $BASE_CONTAINER
LABEL maintainer="Jupyter Project <jupyter@googlegroups.com>"
# Fix DL4006
SHELL ["/bin/bash", "-o", "pipefail", "-c"]
USER root
ARG openjdk_version="11"
RUN apt-get update --yes && \
apt-get install --yes --no-install-recommends \
"openjdk-${openjdk_version}-jre-headless" \
ca-certificates-java && \
apt-get clean && rm -rf /var/lib/apt/lists/*
COPY jars /opt/spark/jars
COPY emr-lib /opt/spark/emr-lib
COPY python /opt/spark/python
COPY bin /opt/spark/bin
COPY examples /opt/spark/examples
RUN mkdir -p /opt/mnt/s3
RUN chmod -R a+w /opt
USER ${NB_UID}
# Install pyarrow
RUN mamba install --quiet --yes \
'pyarrow=4.0.*' \
'pyspark==3.0.1' && \
mamba clean --all -f -y && \
fix-permissions "${CONDA_DIR}" && \
fix-permissions "/home/${NB_USER}"
WORKDIR "${HOME}"scipy notebook image를 기본으로 하고 spark/AWS 관련 jar를 COPY해서 image를 생성합니다. https://github.com/jupyter/docker-stacks 에 pyspark 관련한 image도 있는데 AWS에서 사용하기 위해서는 추가적인 jar 가 필요하기 때문에 위와 같이 구성합니다.
Spark Script for sparkSession in python
- python환경이라 hive-site.xml, core-site.xml, spark-defaults.conf 에 설정을 sparkSession생성시 추가합니다.
- glue metastore를 위해서 "spark.hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory" 를 추가합니다.
from pyspark import SparkConf
from pyspark.sql import SparkSession
import socket
host = socket.gethostbyname(socket.gethostname())
spark1 = SparkSession \
.builder \
.appName("jupyter-test") \
.master("k8s://https://" + k8sMaster ) \
.config("spark.kubernetes.container.image", ecrImage) \
.config("spark.executor.instances","2") \
.config('spark.kubernetes.authenticate.driver.serviceAccountName', saName) \
.config('spark.kubernetes.namespace', namespaceName) \
.config('spark.driver.host', host) \
.config('spark.driver.bindAddress', '0.0.0.0') \
.config('spark.driver.extraClassPath', '/opt/spark/jars/*:/opt/spark/emr-lib/*') \
.config('spark.driver.extraLibraryPath', '/opt/spark/emr-lib/native/') \
.config('spark.executor.extraClassPath', '/opt/spark/emr-lib/*') \
.config('spark.executor.extraLibraryPath', '/opt/spark/emr-lib/native/') \
.config("spark.kubernetes.node.selector.alpha.eksctl.io/nodegroup-name",nodeGroupName) \
.config("spark.hive.metastore.client.factory.class","com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory") \
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \
.config("spark.hadoop.fs.s3.impl", "com.amazon.ws.emr.hadoop.fs.EmrFileSystem") \
.config("spark.hadoop.fs.s3n.impl", "com.amazon.ws.emr.hadoop.fs.EmrFileSystem") \
.config("spark.hadoop.fs.s3bfs.impl", "org.apache.hadoop.fs.s3.S3FileSystem") \
.config("spark.hadoop.fs.s3.buffer.dir","/opt/mnt/s3")\
.enableHiveSupport() \
.getOrCreate()
JupyterHub helm설치 (1.1.1 에서 테스트)
- helm으로 jupyterhub를 설치하고 위에 sparkSession 생성후(위에script)
를 실행하면 다음과 같은 에러가 발생하는데,spark1.sql("show databases").show()
21/07/31 10:24:04 DEBUG EC2ResourceFetcher: An IOException occurred when connecting to service endpoint: http://169.254.169.254/latest/dynamic/instance-identity/document Retrying to connect again. 21/07/31 10:24:06 DEBUG EC2ResourceFetcher: An IOException occurred when connecting to service endpoint: http://169.254.169.254/latest/dynamic/instance-identity/document Retrying to connect again. 21/07/31 10:24:08 DEBUG EC2ResourceFetcher: An IOException occurred when connecting to service endpoint: http://169.254.169.254/latest/dynamic/instance-identity/document Retrying to connect again. 21/07/31 10:24:09 WARN EC2MetadataUtils: Unable to retrieve the requested metadata (/latest/dynamic/instance-identity/document). Failed to connect to service e
http://169.254.169.254/latest/dynamic/instance-identity/document 접속을 할수 없다고 나옵니다. 169.254.169.254 와 관련된 정보는 https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instancedata-data-retrieval.html 에서 확인할수 있는데 ec2 meta정보를 받아오는 API임을 확인할수 있는데 jupyter에서 접속에 문제가 있어보입니다.그래서 jupyterhub helm 에서 value.yaml을 확인해보면
...
cloudMetadata:
# block set to true will append a privileged initContainer using the
# iptables to block the sensitive metadata server at the provided ip.
blockWithIptables: true
ip: 169.254.169.254
networkPolicy:
enabled: true
ingress: []
egress:
# Required egress to communicate with the hub and DNS servers will be
# augmented to these egress rules.
#
# This default rule explicitly allows all outbound traffic from singleuser
# pods, except to a typical IP used to return metadata that can be used by
# someone with malicious intent.
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32
...
value.yaml에 singlueuser 항목에서 network관련 설정을 확인하게 되면 169.254.169.254 ip를 보안관련 문제로 막아놓았습니다. 해당부분 열어주는게 정보보안에서 문제가 있을 여지는 생각해봐야겠지만 우선 spark 의 성공적인 실행을 위해서 위에 부분에서 cloudMetadata.blockWithIptables: false로 변경하고 아래 egress부분은 주석처리를 하면 glue metastore를 사용하는 aws 에서도 성공적으로 spark 을 실행할수 있습니다.